CSCC69 - Final Review #
Winter 2023 #
We both know I shouldn’t be writing a review for this course.
Threads and Processes #
Concurrency #
Running multiple processes at the same time
- Able to run more processes than the number of cores
- Serial execution results in more CPU idle time waiting for I/O
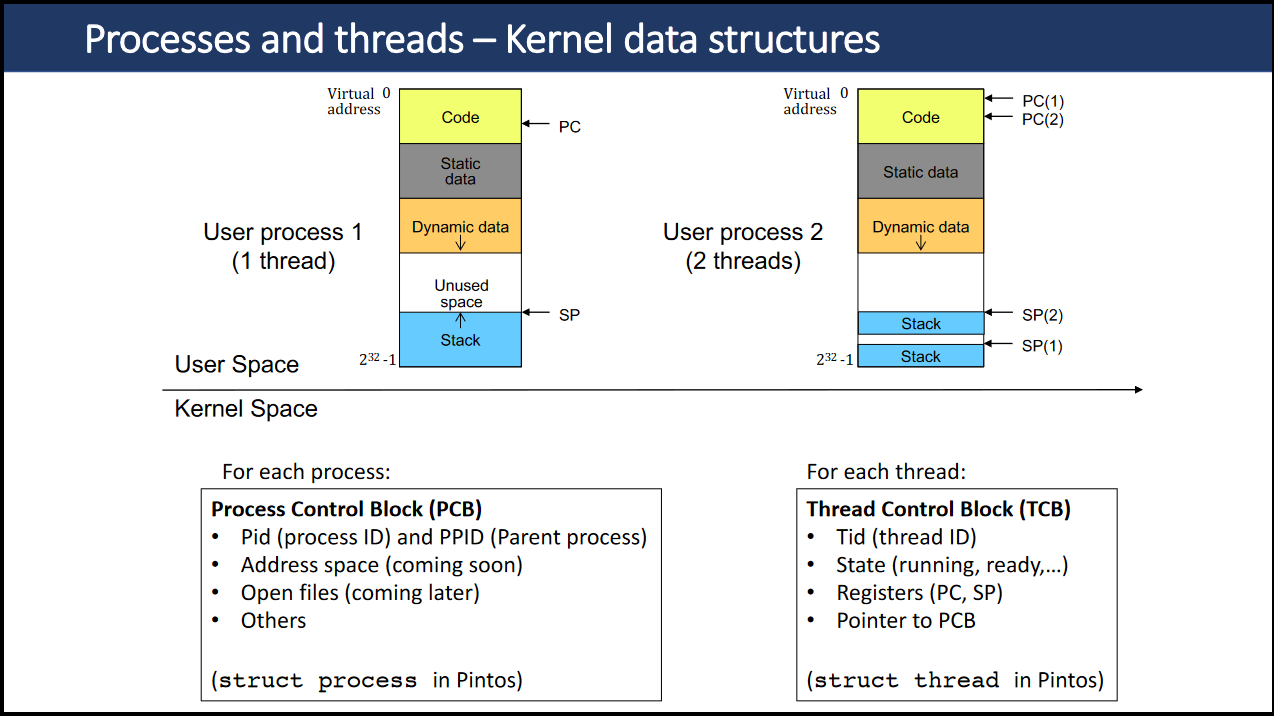
- User threads are 1:1 mapped to kernel threads (
struct thread), can also be many:1 - The OS also has its own kernel threads
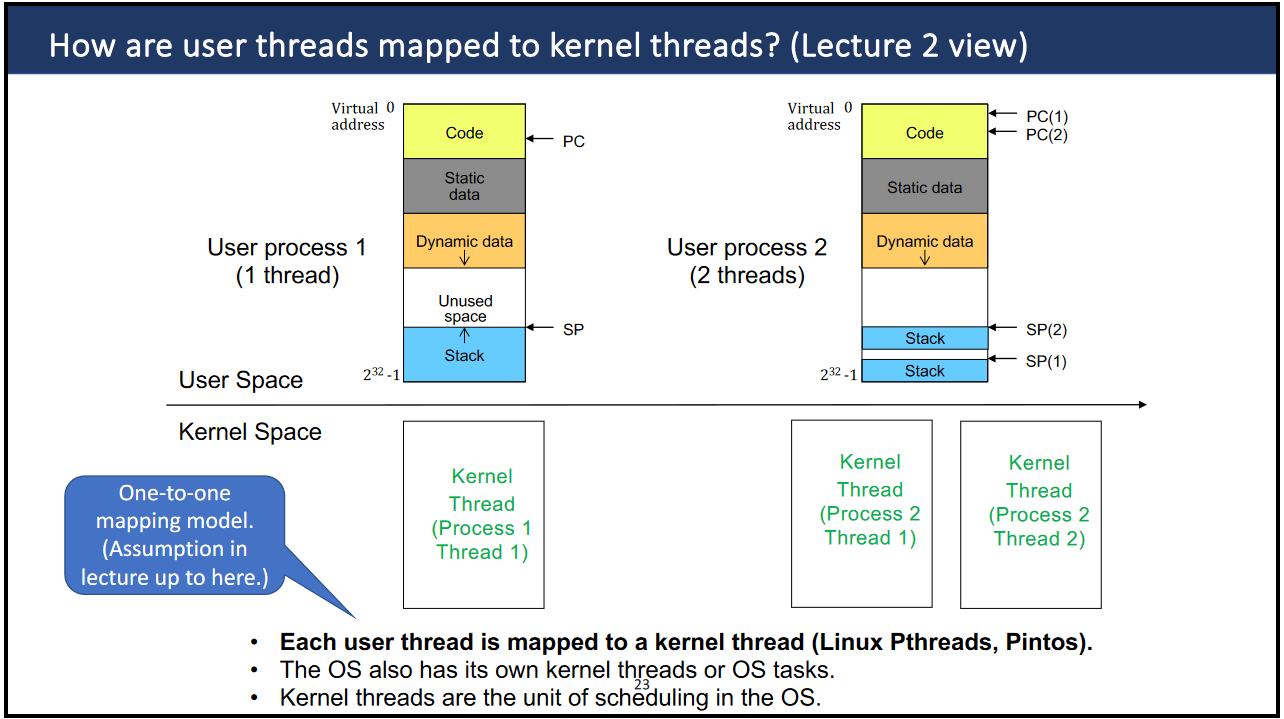
Interrupts #
- CPU stops running current process, saves its state, and runs interrupt handler (
threads/interrupt.c) - External: Programmable Interrupt Controller (PIC) handles hardware interrupts
- Internal: Timer interrupts, Syscalls, Faults (page, segmentation, division by zero)
Synchronization #
- Incrementing and Decrementing are not atomic, may cause race conditions
Critical Section #
- Code that accesses shared data and must be executed atomically
| Requirement | Definition |
|---|---|
| Mutual Exclusion | Only one thread can be in critical section at a time |
| Progress | A thread in the critical section will eventually exit |
| Bounded Waiting | If a thread is waiting to enter critical section, eventually it will |
| Performance | No thread should wait too long to enter critical section |
Disable Interrupts: Technically works, but can cause deadlock (thread hangs forever)
Semaphores: Accessed by multiple threads
- Contains a counter (> 0) and a list of waiting threads
- Before entering critical section, down the semaphore
- After, up the semaphore, waking up another thread
Locks: Acquired and released by a single thread (binary semaphore)
Condition Variables: Waits for a condition to be true
cond_init (&cond); cond_wait (&cond, &lock); // thread calls this to wait for condition cond_signal (&cond); // wakes up one waiter cond_broadcast (&cond); // wakes all threads
Deadlock #
- No process can make progress because each is waiting for an event that only another process can cause
- Avoided by acquiring resources in a fixed order (no circular wait)
- Note: Any three conditions can (likely) result in deadlock, doesn’t have to be all four
| Condition | Definition |
|---|---|
| Mutual Exclusion | One process at a time can use the resource |
| Hold and Wait | A process is holding at least one resource and waiting for additional resources |
| No Preemption | A resource can be released only voluntarily by the process holding it |
| Circular Wait | P1 waiting on P2 waiting on … PN waiting on P1 |
Scheduling #
Thread Lifecycle #
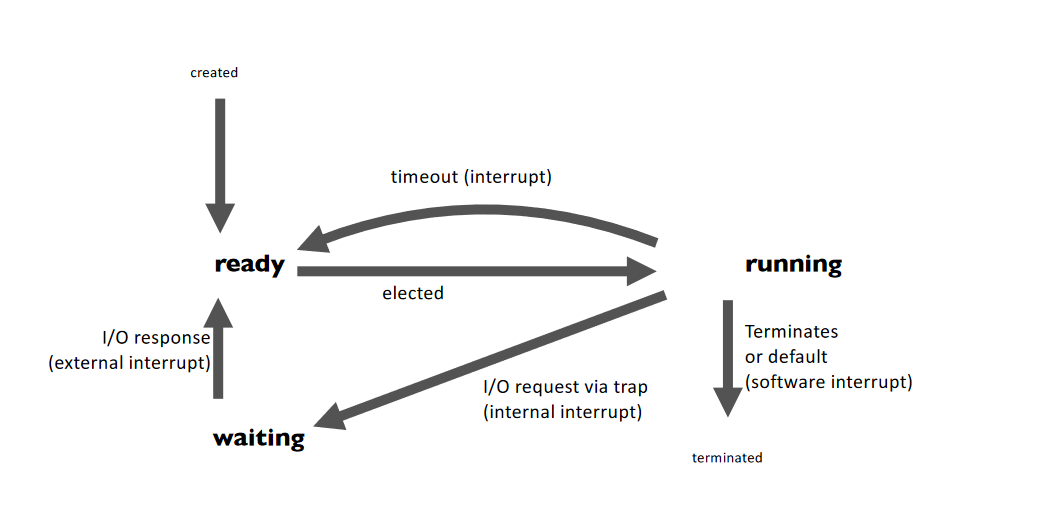
- Scheduling Problem: Given a set of processes, decide which process to run next, and for how long
- Starvation: Thread is prevented from making progress because some other thread has the resources it needs
- i.e. a higher priority thread is preventing the lower priority thread from running
Scheduling Metrics #
| Metric | Definition |
|---|---|
| Throughput | Number of processes that complete per unit time (maximize) |
| Turnaround | time_finished $-$ time_started (minimize) |
| Response | time_responded $-$ time_requested (minimize) |
Scheduling Algorithms #
| Kind | Definition |
|---|---|
| Preemptive | OS can switch to another thread at any time |
| Non-Preemptive | OS can only switch to another thread after the running thread terminates |
First-Come, First-Served (FCFS): Can cause head-of-line blocking (long processes block short processes)
Shortest Job First (SJF): Must know processing time, can cause starvation (short processes starve long processes)
- SRTF: Can consider remaining time instead of total time (preemptive), still leads to starvation
Round Robin (RR): Preempt current thread after time quantum (1-100ms), and continue in FIFO order
- Doesn’t consider a thread’s priority, can cause starvation
Multilevel Feedback Queue Scheduling (MLFQS): Preemptive, priority-based scheduling
- Assigned high priority initially, and priority is decreased after each time quantum
- A Lower priority runs only when the higher priority queue is empty
- If same priority, round robin is used
- After a job uses up its time quantum, it moves to the lower priority queue
- After some time, all jobs are moved back to higher priority
Priority Donation #
- A thread can donate to a lower priority thread
- Eg. Thread H waiting for a lock held by a thread L
- H donates to L, allowing L to schedule and release the lock
- L returns the donation back to H to continue running
NESTED DONATION: "H is waiting on A held by M and M is waiting on B held by L"
|-------------------| |-------------------| |--------------------|
| thread H | |-------------| | thread M | |-------------| | thread L |
| priority: HIGH | | lock A | | priority: MED | | lock B | | priority: LOW |
| waiting_on: A |------>| holder: M |-------->| waiting_on: B |------>| holder: L |-------->| waiting_on: NULL |
|___________________| |_____________| |___________________| |_____________| |____________________|
Virtual Memory #
- Abstraction of physical memory
- Each process has its own virtual address space
- OS maps virtual addresses to physical addresses without the process knowing other processes’ addresses
- Fragmentation: Inability to use memory over time, avoiding this is impossible
- Internal: Fixed size pieces, internal waste of space
- External: Free space is not contiguous, can’t allocate a large block (many small holes)
- Factors required for Fragmentation:
- Different lifetimes: no fragmentation if all processes have same lifetime
- Different sizes: no fragmentation if all processes have same size
| Goal | Definition |
|---|---|
| Protection | Each process has its own virtual address space |
| Efficiency | Reduce memory usage and improve performance |
| Convenience | Allow processes to use memory without worrying about physical memory |
| Extensibility | Allow processes to use more memory than physical memory |
Attempts to Solve Virtual Memory #
Base and Bound Registers
- MMU translates (and verifies) address at runtime
physical_address = virtual_address - base- If
base <= address <= bound, then address is valid, else trap to OS - Causes internal fragmentation, growing process is expensive
Segmentation
- Divide process into segments, each with its own base and bound
- Address is built from segmentation table
- Causes external fragmentation
Simple Paging
- Divide virtual memory into fixed-size pages, physical memory into paged-sized frames
- Each page has a page table entry (PTE) that maps virtual page to physical page
- Eliminates external fragmentation, internal fragmentation is small
- Each memory lookup requires two memory accesses (page table and PTE)
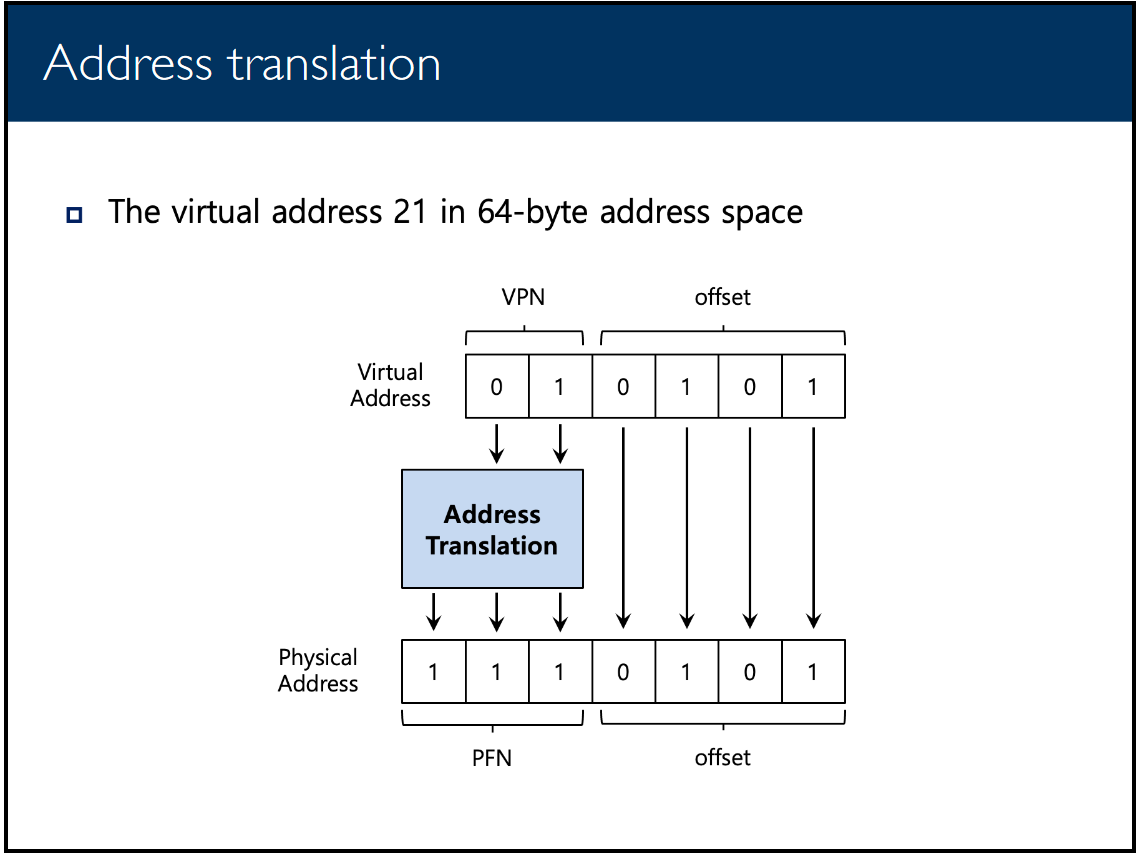
- Multi-Level Paging
- Page directory contains one entry per page table (
pagedir) - Lookup process: (happy path)
- Fetch PTE from PDE
- Fetch page frame from PTE
- Compute physical address from page frame and offset
- If any of the above steps fail, a page fault occurs (
userprog/exception.c:page_fault()) - Allows for page growth, but now requires 3 memory accesses (time-space trade-off)
- Translation Lookaside Buffer (TLB): Cache of recently used PTEs, reduces memory accesses to 2
- High hit rate, maintained by the MMU (hardware is always faster than software)
- Page directory contains one entry per page table (
Page Replacement #
- Swap: Move a page from physical memory to disk
- When a page fault occurs, the OS must choose a page to evict from physical memory into swap
- Page replacement algorithms strive to minimize page fault rate
- Belady’s Anomaly: Having more physical memory does not automatically mean fewer page faults

Page Replacement Algorithms #
- Basic algorithms: FIFO, LRU, LFU, MFU
- Combinations also exist
- Clock Algorithm: Approximation of LRU
list_init (frame_list); // circular
clock_hand = frame_list.head; // some page frame
for (each page access request)
{
if (page in memory) // hit
{
page.accessed = 1;
}
else // miss (eviction)
{
while (clock_hand.accessed == 1)
{
clock_hand.accessed = 0;
clock_hand = clock_hand.next;
}
swap (clock_hand, page);
clock_hand = clock_hand.next;
}
}
- Second Chance: Similar to clock algorithm, head of list after is ready to be evicted
void
second_chance (void)
{
struct thread *cur = thread_current ();
struct frame_table_entry *frame = get_head_frame ();
struct sup_page_entry *spe = frame->spe;
while (pagedir_is_accessed (frame->owner->pagedir, spe->uaddr))
{
pagedir_set_accessed (frame->owner->pagedir, spe->uaddr, false);
// 'rotate' frame to the back of the list
list_remove (&frame->elem);
list_push_back (&frame_table, &frame->elem);
frame = get_head_frame ();
spe = frame->spe;
}
}
Memory Allocation #
- Static: Memory is allocated at compile time (fixed size, stack)
int a[100]; // simple, but restricted - Dynamic: Memory is allocated at runtime (variable size, heap)
char *a = (char *) malloc (100); // contiguous block of memory free (a); // creates fragmentation (need to coalesce)

Allocator Data Structures #
Bitmap: Array of bits, each bit represents a page
- 0 means free, 1 means allocated
- Allocation is slow, requires linear scan to find sequence of zeros
- No need to coalesce
Free List: List of free pages
- Coalescing is required to prevent fragmentation, merge adjacent blocks

Placement Algorithms #
First Fit: Find first free block that is large enough
- Linear scan of free list sorted LIFO/FIFO/address, pick first one that is large enough
- Simple, (often) fastest and most efficient
- May cause fragmentation near start of memory that must be searched repeatedly
Best Fit: Find smallest free block that is large enough
- Minimize fragmentation by allocating space from block that leaves smallest fragment
- Requires linear scan of free list
- Worst Fit: Find largest free block that is large enough (opposite of best fit)
Buddy Allocation: Round up allocations to power of 2 to make management faster
- Fast search and merge (alloc and free)
- Avoids iterating through free list
- Avoids external fragmentation
- Physical pages are kept contiguous

Storage Devices #
Purpose #
It is the OS’s responsibility to abstract storage details
- HDD only knows about platters and sectors, SSD only knows about pages and blocks
- Neither know about files, directories, or processes, but user programs do
Memory/Storage Hierarchy:
- Balance between cost, performance, and capacity
- CPU registers and cache are fastest, but small and expensive
- Hard disk is slow, but large and cheap
- Exploit locality of reference to minimize cost
Persistence:
- ‘Permanent’ storage of data
- Organization, consistency, and management issues are important
Hard Disk Drives #
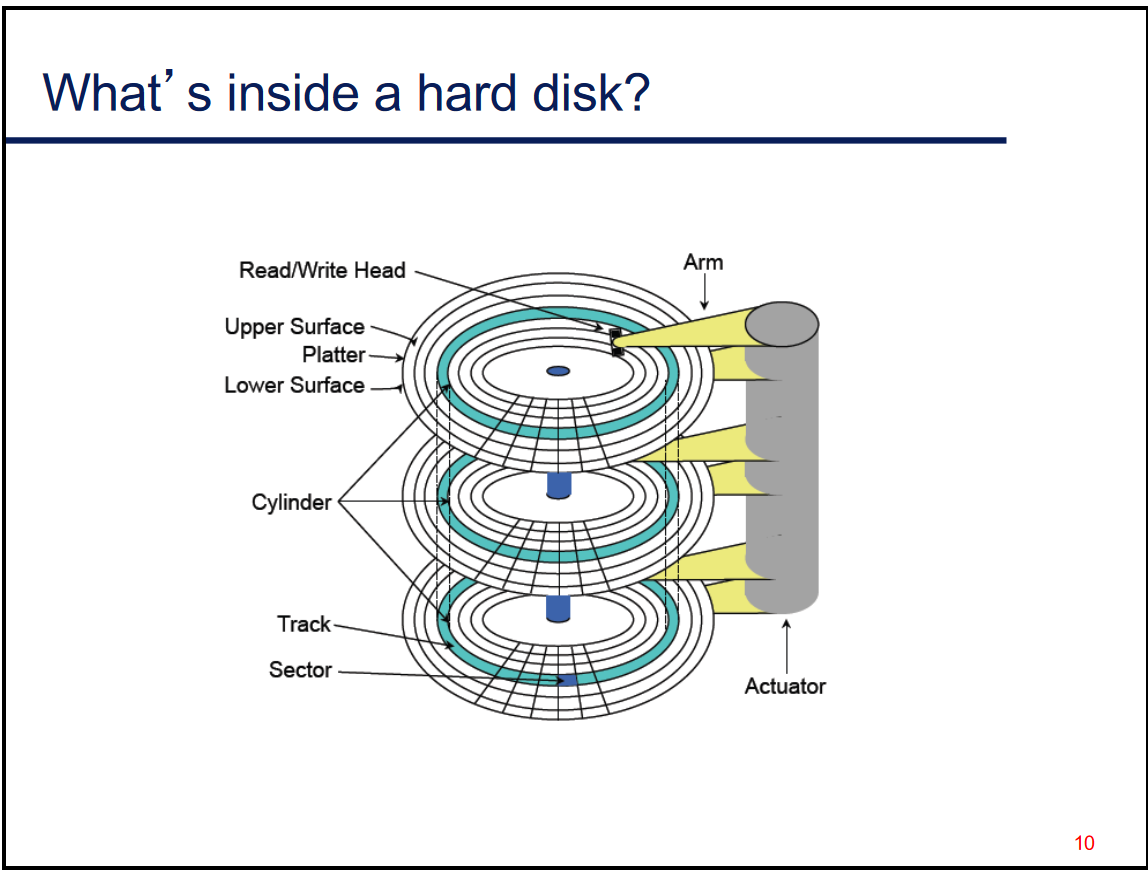
Slow for random access
HDD workloads favor high locality and large request sizes
- Should design FS to generate workloads that have this
Disk service time components:
- Seeking (expensive)
- Rotational Latency (spinning)
- Data transfer (reading/writing)
Disks expose storage as a linear array of blocks
- Blocks are 512 bytes
- Can read/write whole blocks (nothing partial)
- Actual location of block is unknown to the OS
Preventing Failures
Solid State Drives #
Based on NAND flash cells, and have no moving parts
- SLC: Single Level Cell (1 bit per cell)
- QLC: Quad Level Cell (4 bits per cell)
Faster, reliable, and more power efficient than HDD
- But can only be written/erased to a limited number of times
Cells are organized into pages
Pages are organized into Erase Blocks (not the same as disk blocks)
- Writes are only possible to erased pages
Writes are 10x slower than reads, Erases are 10x slower than writes
Erase Blocks are the smallest unit that can be erased
- Causes fragmentation, requires garbage collection, usually done in the background
- GC copies over an entire block to a new block, then erases the old (fragmented) block
- SSDs overprovision to account for this (240GB SSD has 256GB of storage)
GC and Wear levelling (solution to fixed number of writes) case Write Amplification:
- The number of writes to the SSD is greater than the number of writes to the file system

File Systems #
Goals #
- Abstraction: Hide details of storage devices from user programs (files)
- Developed using a generic block layer (does not matter if HDD or SSD)
- Organization: Organize files into directories (logically)
- Sharing: Allow processes, users, and machines to share files
- Security: Protect files from unauthorized access
Disk Layout #
- inode: Data structure to represent a file (
struct inode)- Metadata: File size, permissions, owner, etc.
- Tracks which blocks (on disk) contains the data stored in the file (
struct inode_disk)
Layout Strategies #
Contiguous Allocation: Allocate blocks in a contiguous sequence
- Simple, only need to keep track of offset and length of file
- Causes external fragmentation, gaps when a file is deleted
Linked Allocation: Allocate blocks in a linked list
- Each block points to the next block in the file
- Doesn’t have to be contiguous, need to keep track of first and last block pointer
- Good for sequential access, bad for all others
Indexed Allocation: Multi-level indirect blocks
- ‘Index’ block (indirect, double indirect, triple indirect) points to other blocks
- Need to store the index blocks on disk as well
- Allows for very large and extendable files
- Freemap: Bitmap of free blocks, used to allocate new blocks
- Only need to allocate bit by bit, not contiguously
UNIX File System #
Simple, easy to use, but terrible performance due to lack of locality

Access Paths (UNIX) #
Reading a file from disk #
open ("/foo/bar")“Find the inode for the file (using the path)”- Start at
/, find the inode for the directory - Read block that contains the inode
- Traverse the data in the block to find the inode for
foo - Repeat for
bar - Allocate a file descriptor for the file, and return, checking file permissions
- Start at
read ()“Actually read the file, given the inode”- Read in the first block, use inode to find block location
- If the offset is past EOF, do nothing
- Update inode accessed time
- Update file offset
- Read in the first block, use inode to find block location
When closing the file, deallocate the file descriptor only
Writing a file to disk #
Same
open ()as abovewrite ()“Actually write the file, given the inode”- If the offset is past EOF, need to extend the file
- May need to allocate new blocks, update inode, and freemap
- Read the inode from disk
- Write the data to existing/new blocks
- Depending on indexing strategy, may need to write new indirect blocks
- Update inode with new length, and write serialized inode to disk
- If the offset is past EOF, need to extend the file
Placement Problems in UNIX FS #
Generates long seeks
Data blocks allocated randomly in aging file system
- Initial blocks are allocated contiguously, but later blocks are allocated randomly (fragmentation from deletion)
Inodes allocated far from blocks
- Access paths operations requires going back and forth between inode and data blocks
File Interfaces #
File Descriptors: Managed by the OS
STDINis 0,STDOUTis 1 (reserved)- All other open files are identified by a unique integer
- System calls use the file descriptor to identify the file
- Can also be used for pipes, and sockets
File Pointers: Managed by the C library
FILE *is a pointer to astruct FILE(defined instdio.h)- Contains the file descriptor, and a buffer for reading/writing
- Use
fopen (),fclose (),fread (),fwrite (), … to manipulate - Used for regular files
Questions #
Why do we need to open files before reading/writing them?
- Need to load the file into memory, and allocate a file descriptor, in order to manipulate it
open ()callsfilesys_open (), which callsinode_open (), which loads the serialized inode into memory
- Files occupy multiple blocks, need to load the inode to find the blocks
- We don’t need to load all the blocks at once, just where they are located
- To check permissions of the file, if the user is allowed to read/write to the file
- Need to load the file into memory, and allocate a file descriptor, in order to manipulate it
Why do we need to close files when done with them?
- Resource management: FDs are a limited resource, need to free them up
- File operations may be under a lock, so threads/processes may be blocked
- Security vulnerability, if the file is still open, it can be manipulated by other processes
- Write operations may be written to a buffer, closing the file flushes the buffer
Why did we not have to open STDOUT before using
printf ()?
BSD Fast File System (FFS) #
Improves performance by exploiting locality

Clustering in FFS #
- Put sequential blocks in adjacent sectors
- Place inode near file data in the same cylinder
- Try to keep all inodes in a directory in the same cylinder group (allocation group)
Solutions in FFS #
The Large File Exception
- Problem: Putting all blocks for a large file in the same cylinder group hurts locality
- Use a multi-level index block to store the file’s blocks, store blocks in different cylinder groups
- Indirect blocks: 1 indirect pointer to a block of direct pointers
- Double indirect blocks: 1 indirect pointer to a block of indirect pointers
Problem: Small block size in UNIX (1K)
- Low bandwidth and small max file size
- Use a larger block (4k)
Added Symbolic Links
Problem: Media failures
- Duplicate master block (superblock)
Problem: Device Obliviousness
- Use a generic block layer, so that it doesn’t matter if HDD or SSD
- Modern systems hide device details from the file system

Links #
Hard Links #
- Several dir entires point to the same inode
- UNIX counts number of hard links to an inode
- inode is free’d only when all links are removed (rm)
- If the original file is deleted/moved, the link is not broken
Symbolic (Soft) Links #
- Just a special file (symlink) with a path to another file
- Type of symlink is stored in the inode
- If the original file is deleted/moved, the link is broken, but the file still exists
Buffer Cache #

Read Ahead #
- FS preloads the next block into the buffer cache, predicting that it will be needed soon
- Great for sequential accessed files, unless blocks are scattered across the disk
- FS tries to prevent this during allocation
Protecting Files #
Protection System: Access control mechanism for files
- Owner
- Group (UNIX)
- Permissions
- Read
- Write
- Execute
Access Control List (ACL): List of users and permissions for a file
- For each file, a list of users and their permissions
- For each user, a list of files and their permissions

Crash Consistency #
- File system data structures must persist, retain data on disk even if the system shuts down
- Either unexpectedly (crash, power loss) or planned (graceful shutdown)

- Consider appending to an already open file, this is not atomic and a crash can happen at any of these steps:
- Write to the inode
- Write to the freemap (if allocating a new block)
- Write to the data block
Crash Scenarios #
Only one of the steps succeeds
Only the inode is updated (File Inconsistency)
- Inode points to some data block, thinking that the file has data there
- But it doesn’t, so that data block contains garbage
Only the freemap is updated (Space leak)
- Bitmap claims that the block is allocated, but it is not
- Wasting an entire block that could actually be used
Only the data block is updated
- Not a problem, since the inode is not updated
- OS will not know that the data block is allocated, so it will be overwritten later
Only 2 (out of the 3) steps succeed
Inode and freemap are updated, but data block is not
- The block that the inode claims has data in, contains garbage
- FS metadata is consistent
Inode and data block are updated, but freemap is not
- Block is inconsistent with the freemap, thinking that it is free
- Freemap will (eventually) overwrite the data block, so the data will be lost
Freemap and data block are updated, but inode is not
- Similar to just the data block being updated
- No clue which file the data block is allocated for
- Would not get overwritten, since the freemap knows its allocated
- Inconsistent with the inode, so really just wasting space
Journaling #
A solution to crash consistency
Allows the file system to recover from a crash, by keeping a log of all file system operations
Before performing an operation, write it to the log
If a crash happens, the file system can replay the log to recover
Small section of disk is partitioned just for the journal
- Journal is a circular buffer, so it will eventually overwrite itself (due to finite partition size)
Writing to the log: #
- TxB: Transaction Begin marker
- Contains transaction identifier (TID)
- Physical Loggings: Write the (exact block content) data to the log
- TxE: Transaction End marker
- Contains same TID
Checkpoint #
- Once journal is safely updated, ready to update the actual FS
- Issue the three writes to the FS
- Write the inode
- Write the freemap
- Write the data block
Recovery during checkpoint crash (successful journal log) #
Scan the log for completed transactions
- Find the last TxB and TxE
- All operations between these two markers are part of the same transaction
- Just replay the transaction, since the data was physically logged in the journal
- If TxE is missing, then the transaction is incomplete
- The data was not written to the log, so the update is lost
- The FS is still consistent, since the checkpoint was not reached
Recovery during Journal write crash #
- Internally, the disk may write the journal data in any order (abstraction of sectors to linear blocks)
- TxB and TxE might be written before physical loggings,
- If disk lost power before writing the data blocks, then the transaction is incomplete but may appear complete
Split transaction into two (atomic) transactions: TxB + Phys, and TxE
- If disk loses power during first transaction, no big deal, as if nothing was logged
- If lost during the second transaction, TxE never gets written, so the entire transaction is lost/skipped anyway
One single transaction, but include a Journal Checksum (commit)
- TxB, Phys, Checksum, then TxE
- Checksum is computed from all the data in the transaction (including TxB and TxE)
- When replayed, the entire transaction is valid if the checksum is correct (recompute and compare)

Metadata Journaling #
- Log only the metadata (inode + bitmap) changes
- Data blocks are written to the filesystem directly, not the journal
- Write the data block to the FS
- Journal TxB and Metadata
- Journal Checksum commit
- Journal TxE
- Checkpoint metadata (inode, bitmap)
- FS is consistent if it crashes before this step
- Free: Update the journal superblock (this journal log can be overwritten)
Credits: Professor Bianca Schroeder, University of Toronto